
やるべきことを忘れてる気がするけど、思い出したくないので無視しているすのえです。
ぼーっとスマホを見ていたら、気付けば数時間溶けていた。そんな経験だれしもやるでしょう。
ただ、そのようにして得た情報なんてものはそのまま何の定着もせずに抜け落ちていくものです。
これってあまりにも虚しいことです。なので、深堀りして知識として定着させてみませんか?
我々の味方であるAIは、どんなにくだらない質問にも真面目に考察して返してくれますからね。
このAI対話シリーズは、私がAIと行った議論を記し、自分がより人生を豊かにする日記です。
return false;
ぼーっとインターネットサーフィンをしていたところ、こんな投稿に出会いました。
適当に翻訳すると、「95%の確率で正確な超高速素数判定アルゴリズムを作りました」です。
一枚目の画像には、bool is_prime(int x) { return false; } と関数が定義されていて、
言語的に説明すると、「is_primeは整数xを渡されると、xに関わらず常に偽を返す関数」みたいな。
二枚目の画像ではそれを10万回テストしたところ95%で通過した様子が添付されています。
まず素数判定アルゴリズムで通らないケースがある時点でありえないんですが、ネタなのでヨシ。
アルゴリズムの性能が高く見えるわけ
理由書くのめんどくさいな。AI対話の記事なのでAIにわかりやすくまとめてもらいましょう。
常に「素数でない」と判定するだけでこんなに精度が高くなる理由をまとめて。
まあ、世の中のほとんどの数は素数じゃないからね(笑)
確かに小さい数では結構素数の確率が高くて1から100の間に25個もあるけど、
特に大きな数になるほど、それが素数である割合はどんどん減っていっちゃう。intの最大値である21億まで調べると、素数は全体のたった5%しかないんだ。
画像にある「95.121% test passed」っていうのはintの範囲で正の整数をランダムに10万回出して試したんだろうね。確かにそのくらいになるはず。
だから、さらにテストの範囲を広くしていくとどんどん精度が上がっていくよ。
上限を無限に近づけると、理論上この判定機の精度は100%になるだろうね!
return rand() / RAND_MAX < 1.0 / log(n);
一方、転載先のリプライにはこんな返信もありました。
FZVJwdSTY氏は、新たな素数判定機として以下の関数を提案しています。
bool is_prime(int n) { return (double)rand() / RAND_MAX < 1.0 / log(n); }
これは素数定理に基づいた文脈ですね。これもまあAIに聞いてみますか。解説頼む。
この素数定理を使った関数は何を意味するのか簡単にまとめて。
nが素数である確率は、1 ÷ ln(n) で近似できるという素数定理があるね。
この事実を使って「数を渡されたらそれが素数の確率で真を返す」関数がコレ。
イメージで言うと、
小さいn(=10くらい) → 1/ln(10) ≈ 43% → 結構な確率で「素数!」と言う
大きいn(=1兆くらい) → 1/ln(1兆) ≈ 2.2% → ほぼ「素数じゃない」と言うけど、たまに運任せに「素数!」って言って当たりを狙う感じ。
だからこっちの関数も、最初と同じく本当の素数判定は一切してない。
素数定理で出せる確率を基準にして、運任せで適当に返してるだけの関数だね。
この関数もいい感じにアホでいいね。
こっちのアルゴリズムの性能は?
でも思ったんだけど、コレって素数定理に基づいた返しをすると、
非素数のときに素数って言ったり、本当に素数の時に素数じゃない判定をして、
結局常に素数じゃないと判定するアルゴリズムの方が性能が良くなるんでない?
完全にその通り。
「常にfalse」ならnが無限に大きくなれば正答率100%に発散する(正しい)。
でも素数定理確率版は、実は期待正答率が悪くなるんだ。
「悪い確率を引いて失敗する」せいで、常に偽を返すより性能が落ちる。
簡単な確率で考えてみよう。
例えば N が渡されたとき、M が素数である確率を µ とする。
常に偽を返す場合、その正答率は 1-µ になります。これは当然。
でも、確率μに合わせて真と偽を返す場合、失敗には次の2パターンがあって、
素数じゃないのに素数って適当に判定してしまう「False Negative(FN)」と、
素数なのに素数じゃないと判定してしまう、「False Positive(FP)」がある。
それぞれについて、事前確率と事後確率をかけて足すと失敗率がわかるから、
それを全体の1から引くと、正答率は 1 - 2µ + 2µ² になるね。
μの値は小さいから、常に偽と答える方が必ず高い正答率になるわけだね。
やっぱり。常に偽って答える素数判定機、優秀だなぁ~。
正答率がどう動いていくのか、グラフを描画するプログラムは書ける?
Pythonを使って確率の差を視覚的にわかりやすくするコードを書いたよ。
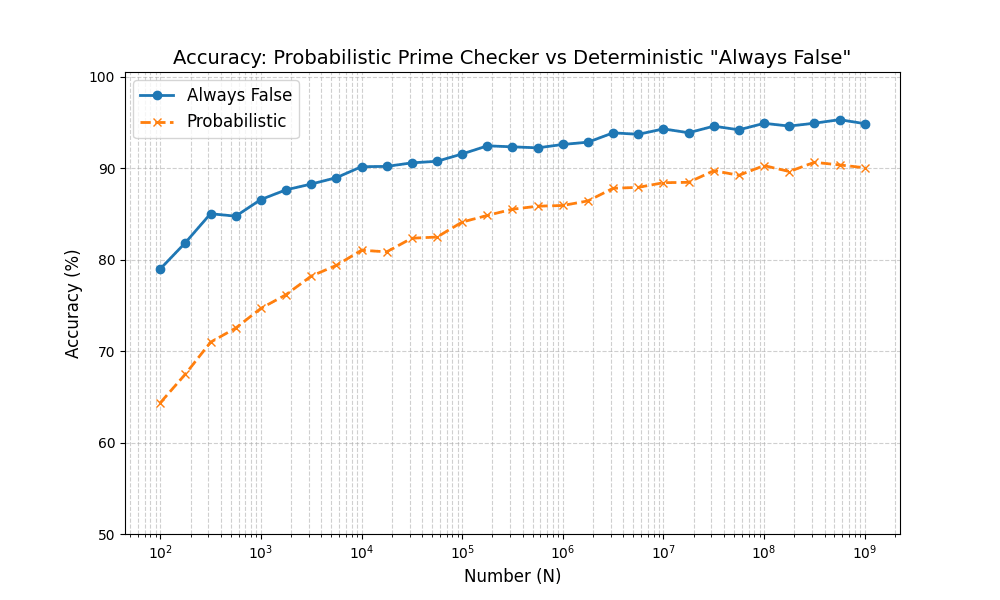
青い折れ線が常に偽を返す方の素数判定機で、オレンジが確率的な方だね。
こう比較すると、確かにどちらもだんだんと正答率が上がってるんだけど、
結局常に偽を返す方がずっと高い確率で正しい答えを返しているのがわかるね。
何回か押し問答するうちに結構いい感じの画像を出力してくれて満足。
というか、プログラムの中で面白そうな素数判定アルゴリズム使ってるじゃん!
ちょっと気になることが増えてきたな。まずはこっちについて深堀りしよう。
ミラー–ラピン素数判定法
プログラムの中で君が面白いアルゴリズムを使ってることに気が付いちゃった。
こんなコメントが書いてある!こんなアルゴリズムがあるんですか!?
確定的ミラー-ラビン素数判定法を用いた高速な素数判定。
n < 4,759,123,141 の範囲で正確と証明されている基底 [2, 7, 61] を使用。いいところに目を付けたね!
「ミラー・ラビン素数判定法 (Miller-Rabin primality test)」は、試し割りを繰り返す愚直な方法とは全く異なるアプローチで計算速度を劇的に改善したんだ!
この判定法は、基本的には「フェルマーの小定理」を拡張したものなんだ。
拡張したフェルマーの小定理を使うと、ある数nをに対して、nが素数ならある2つの条件のどちらかが必ず成立するという状況を作ることができるんだ。
この時、対偶から「条件がどちらも成立しないならnは合成数」とも言えるね。
ただこれは、「nが合成数なら条件はどちらも成立しない」というわけじゃない。
いくつかの「強擬素数」に区分される合成数はこのテストを通過しちゃうんだ!
これに関しては確率的に出現するから、どうしようもない。
そこで、テストに使っている数字を色々変えて試すと、都合のいい結果を出してくれる組み合わせがいくつかある。このうちの一つが、[2,7,61] なんだ。
この3つなら、47億以下の範囲で正確な答えを出すことが既に調べられてる!
これが「確定的ミラー-ラビン素数判定法」と呼ばれる所以だね。
え、ほんとだ!「確定的」じゃん!「確率的」と読み間違えてた!
ってことはじゃあ、この3つがuintの最大値を超えた47億までの範囲の数の素数を判定できるのは、いろんな組み合わせを試して見つけた偶然の結果ってこと?
まあ、誤解を恐れずに言うならそういうことになるね。
この3つの組み合わせは、美しい数学的な公式から導き出されたわけじゃなくて、計算機が総当たり的に発見したのであって、結果だけが説明するものだ。
本当にいろいろな組み合わせで探索した結果、「2のテストをすり抜ける合成数」と「7のテストをすり抜ける合成数」と「61のテストをすり抜ける合成数」の3つをすべて同時に満たす合成数は、4,759,123,141 に到達するまで一つも存在しないことが確認されたことを発見して、この3つが知られるようになったんだね。
これがすごくて、なんと範囲を2乗にして、64bit符号なし整数の範囲で完全に判定できる数の組み合わせも7つで済んだことが2011年に特定されているんだよ!
試し割りをする方法だと、時間計算量のオーダーが√Nだから、64bit整数を判定するには14億回の割り算が必要になって数秒かかるんだけど、ミラー・ラピン法を使うなら時間計算量のオーダーがlog(N)と、1マイクロ秒未満で済むんだ!
(最大でも7×64=448回の剰余演算でどんな数でも判定が済むよ)
はえ~すっごい高速…
でも、常に偽を返す素数判定機にはかなわないね。だって計算1回もしないもん。
時間計算量はO(1)だね(笑)
より性能の良い馬鹿の判定機
じゃあ計算の回数を定数に限定する、馬鹿な議論に戻るか。
常に偽を返す素数判定機は高い精度を出していたと思うんだけど、定数回の計算に絞るとやっぱりこれよりも正答率が高い判定機って作れないの?
結論から言うと、できるよ。
一番簡単な実装はこうなるね。
bool is_prime_better(int n) {
if (n == 2) return true;
return false;
}このアルゴリズムなら、nの大きさに関わらず計算回数が1回だから、定数回。
で、少なくとも最初に一回正しい答えを出してるから、その分だけ確率として、 “常に偽を返す関数”よりかは、厳密には少し高くなってる…と言えるね。
うーん、つまらん正論をぶつけられている気分だ。
だって、長期的に観察すると結局どっちも正答率は同じ速度で収束するじゃん!
収束速度で常に偽の判定機を超えるものは数学的に実現不可能なの?
残念ながら、根本的に上回るアルゴリズムは実現不可能だね。
定数回の計算で、加速度的に増加する合成数と素数を区別することは不可能。
だから、どんな計算を追加しても、正答率をより悪化させるか、正答率のグラフをごくわずかに平行移動させるだけで、収束速度を上げることができない。
この前提を踏まえたうえで、計算量をlog(N)まで引き上げて正答率のグラフがどう変化するかシミュレーションしてみない?
…
締め
なんか議論の主導権を握られて有意義な会話に誘導されそうになったので返答をやめました。
自分の興味のある方向にだけ進むことは良くないことはわかってるけどまあ興味ないんだよな。
いやまあ疑問への回答は得られたので、まあ今回の思い付きはここまでってことで。
皆さんも何かちょっと思いつくことがあったら適当にAIに話を振って、知識を深めましょう。
そして、自分に有利なうちに会話を断ち切ってみましょう。それを繰り返しましょう。
最後に、積み上げてきたAIとの会話を振り返って、自分がどこで会話をやめるか分析するんです。
自分の「興味を失うタイミング」をメタ認知できてるみたいで面白いですよ。
って書いて自分でもやってみたけど想像よりもなんか嫌な気分になった。
なんか自分の今までの人生で醸成されてきた投げ出し癖を突き付けられてるみたいだ。
私は逃げます。自分が積み上げてきた業から。また気が向いたら。さようなら。


コメント